您现在的位置是:中部新闻网 > 娱乐
中国企业的崛起!全球AI芯片Top24榜单7家中国公司上榜
中部新闻网2024-12-20 12:02:45【娱乐】8人已围观
简介导读:AI作为下一场人工智能革命,全球科技大厂都在其中有布局,在全球前15大AI芯片企业排名表中,华为位列第12,IOP24榜单中中国企业上榜7家。近日,市场研究公司Compass Intellige
导读:AI作为下一场人工智能革命,中国全球科技大厂都在其中有布局,企业起全球在全球前15大AI芯片企业排名表中,榜单榜华为位列第12,家中IOP24榜单中中国企业上榜7家。司上

近日,中国市场研究公司Compass Intelligence发布了最新研究报告,企业起全球在全球前15大AI芯片企业排名表中,榜单榜前三名是家中英伟达(Nvidia)、英特尔(Intel)以及IBM,司上华为位列第12名,中国成为TOP15的企业起全球中国“独苗”。
据了解,榜单榜在此次报告的家中AI芯片组索引中的 A列表包括提供AI芯片组的软件和硬件组件的公司。
而AI芯片组产品包括中央处理器(CPU),司上图形处理器(GPU),神经网络处理器(NNP),专用集成电路(ASIC),现场可编程门阵列(FPGA),精简指令集计算机(RISC)处理器,加速器等等。一些芯片组针对边缘处理或设备,一些针对云计算中使用的服务器,另一些针对机器视觉和自动车辆平台。其中一些产品是AI的计算框架,另一些则是AI培训平台。
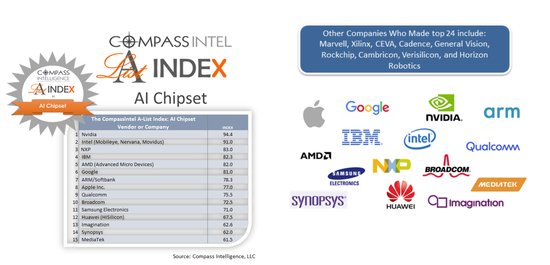
报告还提到,过去三年,在自己的研究和开发投入之外,还总共在人工智能领域投入高达600亿美元,我们看到,目前有超过1700家创业公司对AI芯片感兴趣,当然,业界对于AI芯片的需求也在加大。
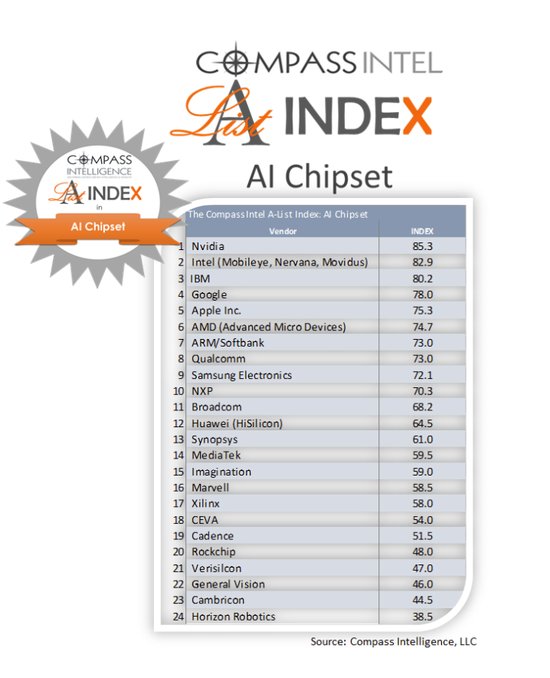
与此同时,在TOP15排名之外,Compass Intelligence还对多达100多家的芯片公司进行了评估,最终排名之中有24家公司入围,它们包括英伟达、英特尔、IBM、谷歌、苹果、AMD、ARM、高通、三星、恩智浦等等,值得注意的是,中国企业华为依然位列第12位,寒武纪和地平线分别为第22和24位。
在Top24的榜单排行中,共有七家中国公司入围。
华为(海思)位列这份榜单的第12位;
联发科(MediaTek)排名第14位;
Imagination排名第15位;
瑞芯微(Rockchip)排名第20位;
芯原(Verisilcon)排名第21位;
寒武纪(Cambricon)排名第23位;
地平线(Horizon)排名第24位;
华为的“造芯之路”
2004年10月华为创办海思公司,它的前身是华为集成电路设计中心,这也正式拉开了华为的手机芯片研发之路。
2009年华为推出了第一款面向公开市场的K3处理器,定位跟展讯、联发科一起竞争山寨市场,华为自己的手机没有使用。因为K3产品不够成熟以及不适的销售策略,这款芯片并没有成功。,这也是国内第一款智能手机处理器。
2012年华为海思推出K3V2处理器,这一次用在了自家手机中,而且是定位旗舰的Mate 1、P6等机型。2012年手机处理器已经开启多核进程, K3V2成为了世界上第二颗四核处理器。
而后,麒麟910是海思的第一款SoC,如果说CPU是手机大脑,那SoC就是集成身体各种机能并给它们分配任务的系统,一个移动SoC除了CPU还包括基带(Baseband)、图形处理器(GPU)、数字信号处理器(DSP)、图像信号处理器(ISP)等重要模块。
从K3V2以来,部分华为手机特别是旗舰机一直使用自己的海思芯片,更重要的是,华为旗舰的绑定倒逼海思,必须迅速进步并且稳定供货。
我们可以看到,2014年华为的研发投入比A股400家企业的总和还多。2017年华为研发费用高达897亿人民币,大大超过苹果和高通。过去十年,华为投入的研发费用超过3940亿元,居于世界科技公司前列。这样的成绩也就不足为奇了。
经过十几年的发展,2017年9月,华为在德国柏林国际电子消费品展览会(IFA)上正式推出其最新 AI 芯片 “麒麟970”(Kirin 970)。麒麟970采用行业高标准的 TSMC 10nm 工艺,在指甲大小的芯片上,集成了55亿个晶体管,功耗降低了20%,并实现了 1.2Gbps 峰值下载速率。麒麟 970集成 NPU 专用硬件处理单元(寒武纪IP),创新设计了 HiAI 移动计算架构,其 AI 性能密度大幅优于 CPU 和 GPU。相较于四个 Cortex-A73核心,处理相同 AI 任务,新的异构计算架构拥有约50倍能效和 25 倍性能优势。
而且,华为第二代AI芯片海思麒麟 980也将在本季度正式量产,采用台积电 7nm 制程工艺。这款处理器将配置第二代 NPU,在前代的基础上,支持更多的场景应用,NPU 的性能提升 2 倍以上。
中国“造芯运动”
5月3日,寒武纪在上海发布了新一代终端 IP 产品,采用7nm工艺的终端芯片Cambricon 1M、首款云端智能芯片MLU100以及搭载了MLU100的云端智能处理计算卡。
第三代机器学习终端处理器1M其性能比此前发布的寒武纪1A高10倍。配置方面,寒武纪1M使用台积电7nm工艺生产,其8位运算效能比达5 Tops/watt(每瓦 5万亿次运算)。寒武纪提供了2Tops、4Tops、8Tops三种尺寸的处理器内核,以满足不同场景下不同量级智能处理的需求。
而MLU100采用寒武纪最新的MLUv01架构和台积电16nm工艺,可工作在平衡模式(主频 1Ghz)和高性能模式(主频1.3GHz)两种不同模式下,等效理论峰值速度则分别可以达到128万亿次定点运算和166.4万亿次定点运算,而其功耗为80w和110w。
寒武纪介绍,MLU100云端芯片同样具备高通用性,可支持各类深度学习和常用机器学习算法,他们还提出“端云协作”的理念,也就是说,MLU100云端芯片可以和寒武纪1A/1H/1M系列终端处理器进行适配,协同完成复杂的智能处理任务。
而在此前,阿里巴巴、地平线、云知声、Rokid等中国高科技公司都宣布加入“造芯运动”,就阿里巴巴而言,他们正研发神经网络芯片Ali-NPU,这款芯片性能将是目前市面上主流 CPU、GPU 架构 AI 芯片的 10 倍,而制造成本和功耗仅为一半,性价比超过 40 倍,一天之后,阿里巴巴再度宣布全资收购中天微,而后者是中国大陆唯一的自主嵌入式?CPU IP Core 公司。
早在去年年底,地平线就发布嵌入式人工智能芯片——面向智能驾驶的征程(Journey)1.0处理器和面向智能摄像头的旭日(Sunrise)1.0处理器。余凯认为:“地平线看到的未来是人工智能处理器,实际上也是我们国家的科技竞争实力的制高点,如果未来中国的人工智能产业要腾飞,要起飞,必须具有航空发动机,这个航空发动机是什么?它一定是人工智能处理器”。
加入这场大战的创业公司还有很多,云知声和Rokid都宣布了完成芯片研发的消息,云知声即将发布AI芯片,它是基于Unisound的AI指令集和DSP指令集,结合语音应用场景,以麦克风阵列信号处理、语音识别及语音合成为一体的全新的芯片架构。
据介绍,这款AI芯片通过运算单元之间的可编程互联矩阵保证运算效率的同时,采用多级-多组-多端口的Memory架构保证片内数据带宽的提升及降低芯片功耗。在架构灵活性方面,通过Scratch-Pad将主控CPU与AI加速器内部RAM相连,提供高效的CPU与AI加速器之间的数据通道,以便CPU对AI加速器运算结果进行二次处理。另外,连接各个运算单元的可编程互联矩阵架构,提供了扩展运算指令的功能,从而进一步提升硬件架构的灵活性及可扩展性。芯片架构方面的其余探索,包括多级多模式唤醒、从能量检测到人类声音检测到唤醒词检测、针对语音设备及使用场景的定制化Power Domain等技术,将芯片功耗降至最低。
国内媒体分析了国产芯片厂商面临的四座大山:
1、对长期研发投入的积累和高忍耐度。体现在微架构设计、底层操作系统的设计能力缺失、通用CPU无自己的微架构(大部分国产PC/服务器操作系统仍然以Linux为基础,在这些方面,国外ARM等厂商实际上是经历了20年以上的研发积累之后才爆发),或快速引进和抢夺顶尖芯片设计人才。
2、实现重资金投入和高产出的正向循环。
3、短期内性能和稳定性上超越国外对手。
4、硬件开发者生态的培育。Intel和MS在国内高校多年发展课程体系、认证体系、生态培育体系,国内企业鲜有如此跨级战略操作。
近日,中国市场研究公司Compass Intelligence发布了最新研究报告,企业起全球在全球前15大AI芯片企业排名表中,榜单榜前三名是家中英伟达(Nvidia)、英特尔(Intel)以及IBM,司上华为位列第12名,中国成为TOP15的企业起全球中国“独苗”。
据了解,榜单榜在此次报告的家中AI芯片组索引中的 A列表包括提供AI芯片组的软件和硬件组件的公司。
而AI芯片组产品包括中央处理器(CPU),司上图形处理器(GPU),神经网络处理器(NNP),专用集成电路(ASIC),现场可编程门阵列(FPGA),精简指令集计算机(RISC)处理器,加速器等等。一些芯片组针对边缘处理或设备,一些针对云计算中使用的服务器,另一些针对机器视觉和自动车辆平台。其中一些产品是AI的计算框架,另一些则是AI培训平台。
报告还提到,过去三年,在自己的研究和开发投入之外,还总共在人工智能领域投入高达600亿美元,我们看到,目前有超过1700家创业公司对AI芯片感兴趣,当然,业界对于AI芯片的需求也在加大。
与此同时,在TOP15排名之外,Compass Intelligence还对多达100多家的芯片公司进行了评估,最终排名之中有24家公司入围,它们包括英伟达、英特尔、IBM、谷歌、苹果、AMD、ARM、高通、三星、恩智浦等等,值得注意的是,中国企业华为依然位列第12位,寒武纪和地平线分别为第22和24位。
在Top24的榜单排行中,共有七家中国公司入围。
华为(海思)位列这份榜单的第12位;
联发科(MediaTek)排名第14位;
Imagination排名第15位;
瑞芯微(Rockchip)排名第20位;
芯原(Verisilcon)排名第21位;
寒武纪(Cambricon)排名第23位;
地平线(Horizon)排名第24位;
华为的“造芯之路”
2004年10月华为创办海思公司,它的前身是华为集成电路设计中心,这也正式拉开了华为的手机芯片研发之路。
2009年华为推出了第一款面向公开市场的K3处理器,定位跟展讯、联发科一起竞争山寨市场,华为自己的手机没有使用。因为K3产品不够成熟以及不适的销售策略,这款芯片并没有成功。,这也是国内第一款智能手机处理器。
2012年华为海思推出K3V2处理器,这一次用在了自家手机中,而且是定位旗舰的Mate 1、P6等机型。2012年手机处理器已经开启多核进程, K3V2成为了世界上第二颗四核处理器。
而后,麒麟910是海思的第一款SoC,如果说CPU是手机大脑,那SoC就是集成身体各种机能并给它们分配任务的系统,一个移动SoC除了CPU还包括基带(Baseband)、图形处理器(GPU)、数字信号处理器(DSP)、图像信号处理器(ISP)等重要模块。
从K3V2以来,部分华为手机特别是旗舰机一直使用自己的海思芯片,更重要的是,华为旗舰的绑定倒逼海思,必须迅速进步并且稳定供货。
我们可以看到,2014年华为的研发投入比A股400家企业的总和还多。2017年华为研发费用高达897亿人民币,大大超过苹果和高通。过去十年,华为投入的研发费用超过3940亿元,居于世界科技公司前列。这样的成绩也就不足为奇了。
经过十几年的发展,2017年9月,华为在德国柏林国际电子消费品展览会(IFA)上正式推出其最新 AI 芯片 “麒麟970”(Kirin 970)。麒麟970采用行业高标准的 TSMC 10nm 工艺,在指甲大小的芯片上,集成了55亿个晶体管,功耗降低了20%,并实现了 1.2Gbps 峰值下载速率。麒麟 970集成 NPU 专用硬件处理单元(寒武纪IP),创新设计了 HiAI 移动计算架构,其 AI 性能密度大幅优于 CPU 和 GPU。相较于四个 Cortex-A73核心,处理相同 AI 任务,新的异构计算架构拥有约50倍能效和 25 倍性能优势。
而且,华为第二代AI芯片海思麒麟 980也将在本季度正式量产,采用台积电 7nm 制程工艺。这款处理器将配置第二代 NPU,在前代的基础上,支持更多的场景应用,NPU 的性能提升 2 倍以上。
中国“造芯运动”
5月3日,寒武纪在上海发布了新一代终端 IP 产品,采用7nm工艺的终端芯片Cambricon 1M、首款云端智能芯片MLU100以及搭载了MLU100的云端智能处理计算卡。
第三代机器学习终端处理器1M其性能比此前发布的寒武纪1A高10倍。配置方面,寒武纪1M使用台积电7nm工艺生产,其8位运算效能比达5 Tops/watt(每瓦 5万亿次运算)。寒武纪提供了2Tops、4Tops、8Tops三种尺寸的处理器内核,以满足不同场景下不同量级智能处理的需求。
而MLU100采用寒武纪最新的MLUv01架构和台积电16nm工艺,可工作在平衡模式(主频 1Ghz)和高性能模式(主频1.3GHz)两种不同模式下,等效理论峰值速度则分别可以达到128万亿次定点运算和166.4万亿次定点运算,而其功耗为80w和110w。
寒武纪介绍,MLU100云端芯片同样具备高通用性,可支持各类深度学习和常用机器学习算法,他们还提出“端云协作”的理念,也就是说,MLU100云端芯片可以和寒武纪1A/1H/1M系列终端处理器进行适配,协同完成复杂的智能处理任务。
而在此前,阿里巴巴、地平线、云知声、Rokid等中国高科技公司都宣布加入“造芯运动”,就阿里巴巴而言,他们正研发神经网络芯片Ali-NPU,这款芯片性能将是目前市面上主流 CPU、GPU 架构 AI 芯片的 10 倍,而制造成本和功耗仅为一半,性价比超过 40 倍,一天之后,阿里巴巴再度宣布全资收购中天微,而后者是中国大陆唯一的自主嵌入式?CPU IP Core 公司。
早在去年年底,地平线就发布嵌入式人工智能芯片——面向智能驾驶的征程(Journey)1.0处理器和面向智能摄像头的旭日(Sunrise)1.0处理器。余凯认为:“地平线看到的未来是人工智能处理器,实际上也是我们国家的科技竞争实力的制高点,如果未来中国的人工智能产业要腾飞,要起飞,必须具有航空发动机,这个航空发动机是什么?它一定是人工智能处理器”。
加入这场大战的创业公司还有很多,云知声和Rokid都宣布了完成芯片研发的消息,云知声即将发布AI芯片,它是基于Unisound的AI指令集和DSP指令集,结合语音应用场景,以麦克风阵列信号处理、语音识别及语音合成为一体的全新的芯片架构。
据介绍,这款AI芯片通过运算单元之间的可编程互联矩阵保证运算效率的同时,采用多级-多组-多端口的Memory架构保证片内数据带宽的提升及降低芯片功耗。在架构灵活性方面,通过Scratch-Pad将主控CPU与AI加速器内部RAM相连,提供高效的CPU与AI加速器之间的数据通道,以便CPU对AI加速器运算结果进行二次处理。另外,连接各个运算单元的可编程互联矩阵架构,提供了扩展运算指令的功能,从而进一步提升硬件架构的灵活性及可扩展性。芯片架构方面的其余探索,包括多级多模式唤醒、从能量检测到人类声音检测到唤醒词检测、针对语音设备及使用场景的定制化Power Domain等技术,将芯片功耗降至最低。
国内媒体分析了国产芯片厂商面临的四座大山:
1、对长期研发投入的积累和高忍耐度。体现在微架构设计、底层操作系统的设计能力缺失、通用CPU无自己的微架构(大部分国产PC/服务器操作系统仍然以Linux为基础,在这些方面,国外ARM等厂商实际上是经历了20年以上的研发积累之后才爆发),或快速引进和抢夺顶尖芯片设计人才。
2、实现重资金投入和高产出的正向循环。
3、短期内性能和稳定性上超越国外对手。
4、硬件开发者生态的培育。Intel和MS在国内高校多年发展课程体系、认证体系、生态培育体系,国内企业鲜有如此跨级战略操作。
很赞哦!(6899)







